在过去的10多年间,查找,或者说是搜索这一项技术,造就了不少明星企业,诸如前期的yahoo、后来居上的google,以及中国本土企业百度,都在搜索这一领域获取了巨大的市场利益。本文简单的论述一些关于查找的基础数据结构。
查找中很重要的一个概念就是:关键字。查找的定义为:根据某个给定的值,在查找表(也就是数据库)中确定一个其关键字等于给定值的记录的过程。
1、顺序查找(Sequential Search)
顺序查找是最基本的查找技术,它的实现原理也最简单:从表中第一个(或最后一个)记录开始,逐个进行记录的关键字和给定值的比较,若某一次比较结果相等,则查找成功;若查找到最后一个(或第一个)记录,仍不相等,则查找不成功。下面为一段顺序表查找的算法:
/* 顺序查找,a为数组,n为要查找的数组长度,key为要查找的关键字 */
int Sequential_Search(int *a, int n, int key)
{
int i;
for (i = 1; i <= n; i++) {
if (a[i] == key) {
return i;
}
}
return 0;
}很简单的一段代码,就是对给出的数据,逐项比较就行了。但这段代码其实有一处比较多余,就是在for循环中,每一次比较之后,还需要将当前的下标与边界值进行比较,这是完全可以省掉的。下面来看优化后的代码。
/* 带哨兵的顺序查找 */
int Sequential_Search2(int *a, int n, int key)
{
int i;
a[0] = key; /* 设置a[0]为关键字值,称之为“哨兵” */
i = n; /* 设置循环从尾部开始 */
while (a[i] != key) {
i--;
}
return i; /* 返回0则说明查找失败 */
}这里是在查找方向的尽头放置了一个“哨兵”,从而免去了在查找过程中每一次比较后都要判断查找位置是否越界的小技巧。看似与之前的差别不大,但如果总数据量很大时,效率就会提高不少,是非常好的编程技巧。
总结:顺序查找方式算法简单,但对于海量数据,效率则非常低,毕竟要从头至尾轮一遍。实际上,对于我们现在所用的搜索引擎也好,或是数据库也好,只要是数据量比较大,是肯定不会用这种简单的查找方式的,太费时间了。
2、折半查找(Binary Search)
定义:折半查找又称为二分查找。其前堤为数据表中记录必须是关键码有序(一般为从小到大有序),线性表必须采用顺序存储。折半查找的基本思想为:每一次取数据表中的中间记录作为比较对象,若给定值等于中间记录关键字,则查找成功;若给定值小于中间记录关键字,则在中间记录的左半区继续查找;若给定值大于中间记录关键字,则在中间记录的右半区继续查找。不断重复上述过程,直到查找成功,或者失败。
下面为折半查找的算法:
/* 折半查找 */
int Binary_Search(int *a, int n, int key)
{
int low, high, mid;
low = 1; /* 定义最低下标为记录首位 */
hign = n; /* 定义最高下标为记录末位 */
while (low <= high) {
mid = (low + high) / 2; /* 折半 */
if (key < a[mid]) {
high = mid - 1; /* 若查找值比中值小,则最高下标调整到中位下标小一位 */
} else if (key > a[mid]) {
low = mid + 1; /* 若查找值比中值大,则最低下标调整到中位下标大一位 */
} else {
return mid; /* 若相等则说明mid即为查找到的位置 */
}
}
return 0;
}这段代码也很简单,了解折半查找的原理就可以看明白了,最后循环结束的条件是:要么找到了,要么就是一层一层的二分区间查找下去,直到最后一层不可分的二分区间找完了,还是没有找到。
总结:折半查找的效率远高于前面的顺序查找。但它的前堤是必须关键字有序且顺序存储。而且它不适用于频繁进行插入或删除操作的数据表。
3、插值查找(Interpolation Search)
折半查找算法中,折半代码为:mid = (low + high) / 2;
做一个等式变换后能够得到:
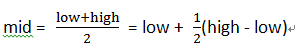
算法科学家们对后面的这个1/2进行改进,就有了下面的计算方案:
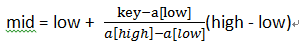
将1/2改成了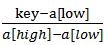 有什么道理呢?假设a[11] = {0, 1, 16, 24, 35, 47, 59, 62, 73, 88, 99},low = 1,high = 10,则a[low] = 1,a[high] = 99,如果我们要找key = 16,则使用原来折半的作法,我们需要3次才可以得到结果(第1次查到47,第2次查到24,第3次查到16),但如果用新方法, = (16 - 1) / (99 - 1) ≈ 0.153,即mid ≈ 1 + 0.153 * (10 - 1) = 2.377,取整得到mid = 2,我们只需要2次查找就能得到结果了,显然提高了查找的效率。也就是说,我们只要将折半查找算法的代码更改一下就可以了,如下:
有什么道理呢?假设a[11] = {0, 1, 16, 24, 35, 47, 59, 62, 73, 88, 99},low = 1,high = 10,则a[low] = 1,a[high] = 99,如果我们要找key = 16,则使用原来折半的作法,我们需要3次才可以得到结果(第1次查到47,第2次查到24,第3次查到16),但如果用新方法, = (16 - 1) / (99 - 1) ≈ 0.153,即mid ≈ 1 + 0.153 * (10 - 1) = 2.377,取整得到mid = 2,我们只需要2次查找就能得到结果了,显然提高了查找的效率。也就是说,我们只要将折半查找算法的代码更改一下就可以了,如下:
mid = low + (high - low) * (key - a[low]) / (a[high] - a[low]); /* 插值 */
至于此处,为什么要将1/2改成,我也不明白,这些事情是算法科学家们来做的,他们做理论研究与创新,而像我们这种做工程的人,大可不必纠结于这个公式是怎么推导出来的,我们做应用的,只要能够会用就可以了,毕竟不是所有人都有能力去推导公式,而且,就算你能够推导,像这种别人已经造出来的轮子,又何必去花时间重复造呢。
现在我们来看插值查找的定义:插值查找是根据要查找的关键字key与查找表中最大最小记录的关键字比较后的查找方法,其核心就在于插值的计算公式。
4、斐波那契查找(Fibonacci Search)
这个我没太看明白,就先不说了,如果后面看懂了,再补上。
5、线性索引查找
前面的几种查找方法都是基于有序的基础之上的,然而实际生活中,大部分数据都不可能一直保持有序的,这时,就需要用到索引。
定义:索引就是把一个关键字与它对应的记录相关联的过程。
线性索引分3种:稠密索引、分块索引、倒排索引。
稠密索引。是指在线性索引中,将数据集中的每个记录对应一个索引项,且索引项一定是按照关键码有序的排列。索引项有序就可以利用前面介绍的有序查获算法,但对于大量数据的表来说,索引规模会很大,从而导致效率很低。
分块索引。这个可以看图书馆的图书分类方式,它就是分块索引,图书馆内的书籍分成很多门类,诸如计算机、行政管理、经济、文学等等。分块索引需要满足两个条件:块间有序、块内无序(书上是这么说的,个人认为其实不一定要求块内无序,有序的话查找起来更为方便,像我以前大学图书馆,图书不仅分块有序,块内也是按照序号进行排列的)。分块索引的索引项结构分为三个数据项:
(1)最大关键码:它存储每一块中最大的关键字;
(2)存储了块中的记录个数,以便于循环时使用;
(3)用于指向块首数据元素的指针,便于开始对这一块中记录进行遍历。
分块索引分两步进行:
(1)在分块索引表中查找要查关键字所在的块。由于块间有序,所以我们可以使用前文介绍的有序查找算法。
(2)根据块首指针找到相应的块,并在块中顺序查找关键码。这里用顺序查找的原因是因为块内无序,只能顺序查找。
倒排索引。这是一种不是由记录来确定属性值,而是由属性值来确定记录位置的索引方式。它的通用结构是:
(1)次关键码(它和数据元素的关系不是一对一,而是一对多,即可以通过它来识别多个数据元素)
(2)记录号表
其中,记录号表存储具有相同次关键字的所有记录的记录号(可以是指向记录的指针或该记录的主关键字)。
最后,实际的搜索技术远远不是上面介绍的这么简单,比方说,你输入一个关键字,搜索引擎只会返回前20条搜索到的记录,本次搜索就结束了,如果你还想看更多的记录,那可能需要点击下一页。比如百度,我们搜索某一关键字,它一般返回的记录在10条左右,我试着搜索了不同的关键字,大部分都是10条以内,然而有些不止10条,这是为什么呢?我仔细看了下,原来真正的搜索记录还是只有10条,而多出来的那几条,则是百度投放的广告,前3条是电商广告,最后2条也是电商广告,一次搜索返回10条内容,另外还附加了5条广告内容,我也真是服了。
(本文完)
参考资料:
[1]程杰.大话数据结构[M].北京:清华大学出版社,2011,6
